🎧 Podcast version available Listen on Spotify →
Eight people published a paper on June 12, 2017.
It was about translation. Specifically, how to translate English to German more efficiently. Academic stuff. The kind of thing that gets cited in other papers and discussed at conferences nobody outside the field attends.
The paper was called “Attention Is All You Need.”
You’ve never read it. Most people building with AI right now have never read it. And yet everything they’re building runs on what those eight people figured out on a Monday in 2017.
What Came Before
To understand why the paper matters, you need to understand what it replaced.
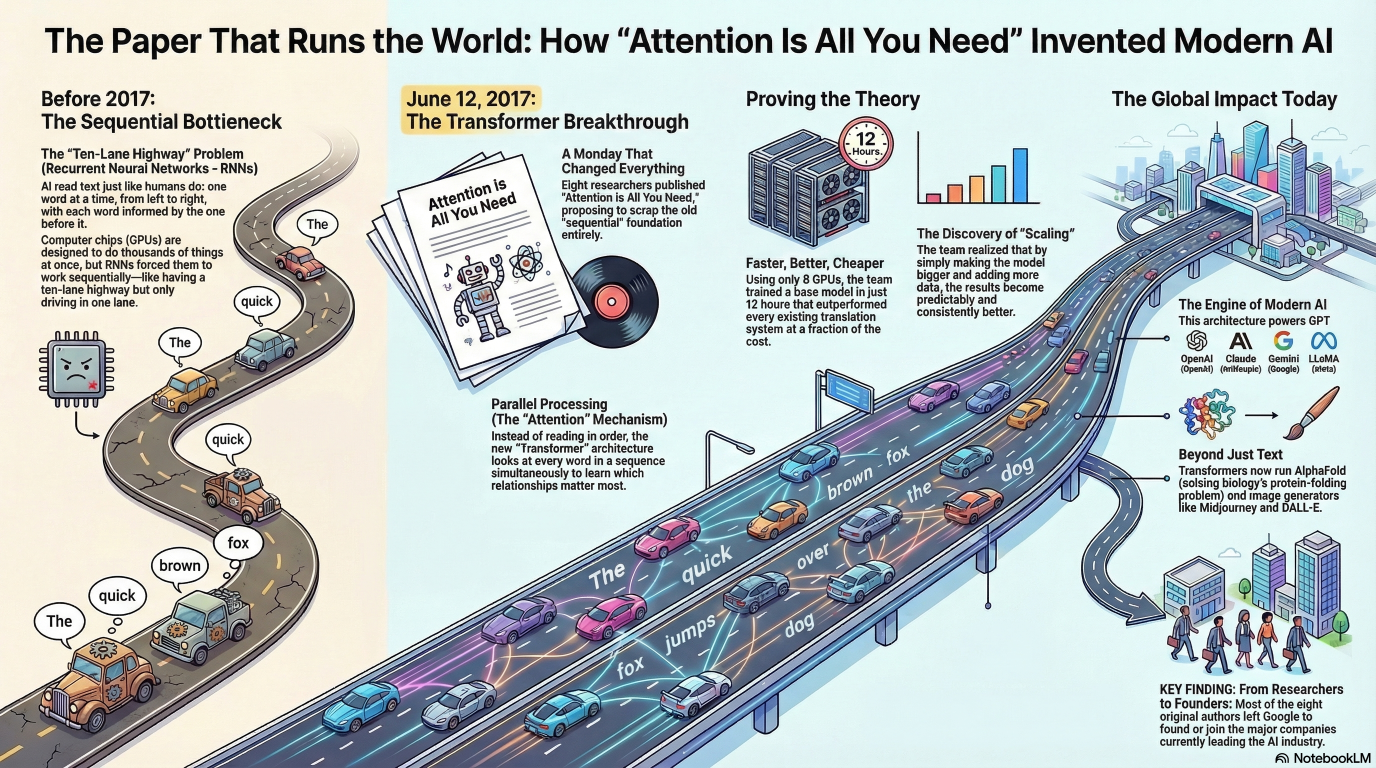
Before 2017, the dominant approach to language AI was recurrent neural networks — RNNs. The idea was simple: process language the way humans read it. One word at a time. Left to right. Each word informed by everything that came before.
It worked. But it had a fundamental problem.
Sequential processing can’t be parallelized. You have to finish word one before you start word two. On a GPU — which is designed to do thousands of things simultaneously — that’s like buying a ten-lane highway and driving in one lane.
Slow. And slower as sequences got longer.
Everyone knew this was a problem. The question was what to replace it with.
The Idea Nobody Believed
One of the eight authors, Jakob Uszkoreit, had a hypothesis.
What if you didn’t need recurrence at all? What if attention — the mechanism that lets a model focus on relevant parts of a sequence — was sufficient on its own?
His own father, a well-known computational linguist, was skeptical.
The field was skeptical.
Recurrence was the foundation. You don’t just remove the foundation.
Except they did.
What They Proposed
The Transformer architecture replaced sequential processing with parallel processing.
Instead of reading left to right, it reads everything at once. Every word attends to every other word simultaneously. The model learns which relationships matter and how much.
The name “Transformer” was chosen because Jakob liked the sound of it. The early design document included illustrations from the Transformers franchise. The team called themselves Team Transformer.
This is how world-changing technology gets named. Not in a strategy meeting. In a document with cartoon robots.
The title — “Attention Is All You Need” — was a reference to the Beatles song “All You Need Is Love.” A joke. Also, accidentally, a precise technical description of what they’d built.
The Numbers That Proved It
The results were hard to argue with.
Trained on a single machine with eight GPUs, the base model ran for twelve hours. The results beat everything that existed. Not slightly — substantially. At a fraction of the training cost.
The architecture was more parallelizable, faster to train, and more scalable than anything before it.
Scaling was the key word. Bigger model, more data, more compute — better results. Consistently. Predictably.
That property — that you could make it better by making it bigger — is what unlocked everything that came next.
What Came After
GPT. BERT. T5. PaLM. LLaMA. Claude. Gemini.
All Transformers.
AlphaFold — the system that cracked protein folding, one of biology’s hardest problems. Transformer.
Midjourney, DALL-E, Stable Diffusion — image generation models. Transformer architecture underneath.
The voice assistant on your phone. The autocomplete in your email. The recommendation system deciding what you watch next.
Eight people. One paper. One Monday in 2017.
What They Didn’t Know
Here’s what’s worth sitting with.
The paper was about translation. That was the use case. Improve machine translation between English and German.
At the end of the paper, the authors noted the architecture might generalize. They mentioned question answering. They mentioned what they called “multimodal generative AI” — though they didn’t call it that yet.
They were right. But even they didn’t fully see it.
The architecture they built to translate sentences between languages ended up being the architecture that generates images, writes code, diagnoses diseases, and runs the chatbots half the world is now using daily.
That’s not unusual in science. The people who build the thing rarely see all the ways the thing will be used.
But it’s worth remembering when someone tells you a new paper is “just about” a narrow technical problem.
Why It Matters To Know This
Most people using AI right now think of it as a product.
Something you log into. Something with a chat interface. Something that answers questions.
Understanding that all of it runs on one architecture — an architecture built by eight people to solve a translation problem — changes how you think about what’s happening.
It’s not magic. It’s not inevitable. It’s the output of specific decisions made by specific people solving a specific problem in a specific way.
And those decisions compound.
The eight authors scattered after the paper. Most left Google. They went on to found or join OpenAI, Cohere, Character.ai, and other companies now at the center of the AI industry.
They built the architecture. Then they built the industry that runs on it.
The question isn’t what AI does.
The question is who’s writing the 2026 papers that nobody is reading yet.